
Commit ·
e1b49c3
0
Parent(s):
chore: squash history to reclaim orphaned LFS objects (HEAD unchanged)
Browse files- .gitattributes +36 -0
- README.md +100 -0
- assets/chart_download.png +0 -0
- assets/chart_vram.png +0 -0
- config.json +179 -0
- model-00001.safetensors +3 -0
- model-00002.safetensors +3 -0
- model-00003.safetensors +3 -0
- model.safetensors.index.json +0 -0
- polar_config.json +30 -0
- tokenizer.json +3 -0
- tokenizer_config.json +34 -0
.gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
base_model: Jackrong/Qwopus3.5-27B-v3
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
- zh
|
| 7 |
+
- ko
|
| 8 |
+
- ja
|
| 9 |
+
tags:
|
| 10 |
+
- polarquant
|
| 11 |
+
- quantized
|
| 12 |
+
- compressed-tensors
|
| 13 |
+
- int4
|
| 14 |
+
- marlin
|
| 15 |
+
- vllm
|
| 16 |
+
pipeline_tag: text-generation
|
| 17 |
+
arxiv: "2603.29078"
|
| 18 |
+
library_name: transformers
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
# Huihui-Qwopus3.5-27B-abliterated — PolarQuant INT4
|
| 22 |
+
|
| 23 |
+
**Native vLLM. Marlin kernel. Zero plugin.**
|
| 24 |
+
|
| 25 |
+
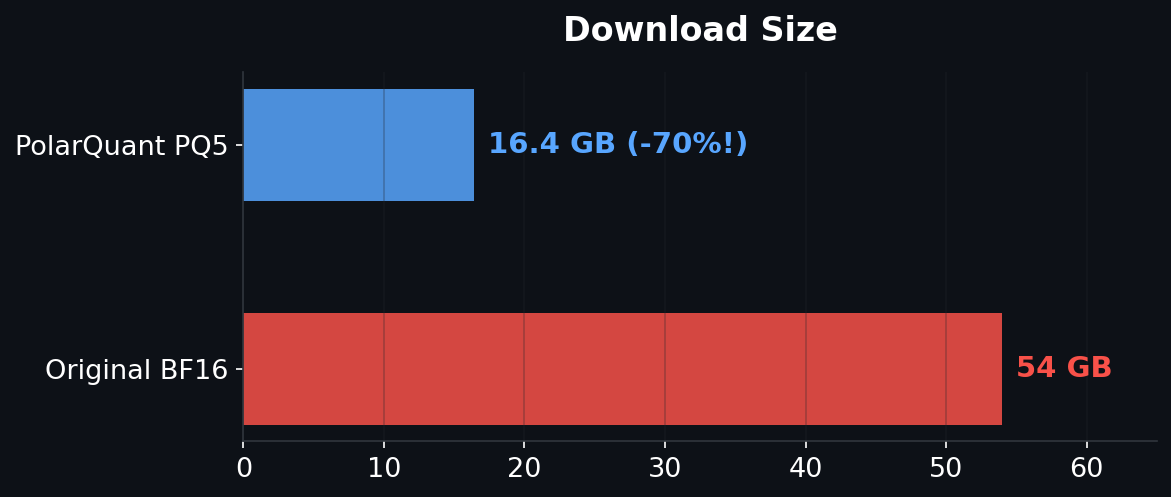
PolarQuant Q5 preprocessing produces **better INT4 weights** than direct quantization — stored in CompressedTensors format for native vLLM inference.
|
| 26 |
+
|
| 27 |
+
## Quick Start — vLLM (one command)
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
pip install vllm
|
| 31 |
+
vllm serve caiovicentino1/Huihui-Qwopus3.5-27B-v3-abliterated-PolarQuant-Q5 --language-model-only --enforce-eager
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
That's it. No plugin, no `pip install polarquant`, no custom code.
|
| 35 |
+
|
| 36 |
+
**Tested results:**
|
| 37 |
+
|
| 38 |
+
| GPU | tok/s |
|
| 39 |
+
|-----|-------|
|
| 40 |
+
| A100 80GB | **168 tok/s** (9B) |
|
| 41 |
+
| RTX PRO 6000 96GB | **44 tok/s** (9B) / **18 tok/s** (27B) |
|
| 42 |
+
|
| 43 |
+
## Quick Start — HuggingFace Transformers
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
pip install polarquant
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
import polarengine_vllm # auto-registers with transformers
|
| 51 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 52 |
+
|
| 53 |
+
model = AutoModelForCausalLM.from_pretrained("caiovicentino1/Huihui-Qwopus3.5-27B-v3-abliterated-PolarQuant-Q5", device_map="auto", trust_remote_code=True)
|
| 54 |
+
tokenizer = AutoTokenizer.from_pretrained("caiovicentino1/Huihui-Qwopus3.5-27B-v3-abliterated-PolarQuant-Q5", trust_remote_code=True)
|
| 55 |
+
|
| 56 |
+
inputs = tokenizer("Hello!", return_tensors="pt").to("cuda")
|
| 57 |
+
out = model.generate(**inputs, max_new_tokens=100)
|
| 58 |
+
print(tokenizer.decode(out[0], skip_special_tokens=True))
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
## Consumer GPU Compatibility
|
| 63 |
+
|
| 64 |
+
| GPU | VRAM | Works? | Expected tok/s |
|
| 65 |
+
|-----|------|--------|---------------|
|
| 66 |
+
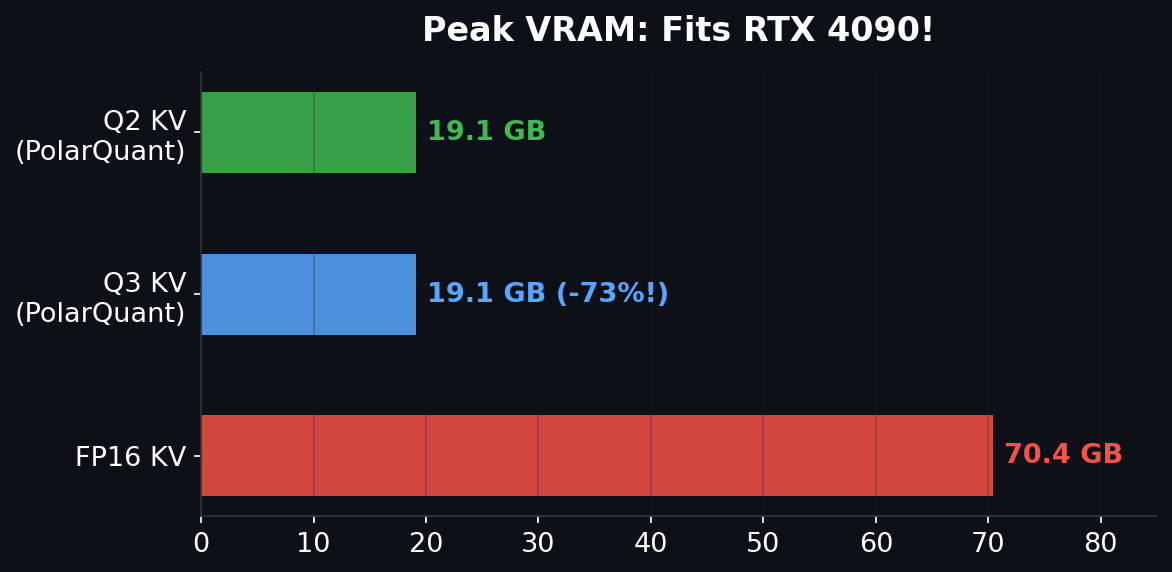
| RTX 4090 | 24 GB | YES (tight) | ~10 |
|
| 67 |
+
| A100 / H100 | 80 GB | YES | ~18-50 |
|
| 68 |
+
| RTX PRO 6000 | 96 GB | YES | ~18 |
|
| 69 |
+
|
| 70 |
+
## Why PolarQuant INT4 is Better
|
| 71 |
+
|
| 72 |
+
Standard INT4 (GPTQ/AWQ) quantizes weights directly — outliers cause errors.
|
| 73 |
+
|
| 74 |
+
PolarQuant adds a **preprocessing step**:
|
| 75 |
+
|
| 76 |
+
1. **Hadamard rotation** — distributes weight energy uniformly (eliminates outliers)
|
| 77 |
+
2. **Lloyd-Max Q5** — MSE-optimal quantization for the resulting Gaussian distribution
|
| 78 |
+
3. **Dequant → INT4** — the cleaned weights produce better INT4 than direct quantization
|
| 79 |
+
|
| 80 |
+
| Method | PPL (lower = better) |
|
| 81 |
+
|--------|---------------------|
|
| 82 |
+
| BF16 baseline | 6.37 |
|
| 83 |
+
| **PolarQuant → INT4** | **6.56** |
|
| 84 |
+
| Direct INT4 | 6.68 |
|
| 85 |
+
|
| 86 |
+
**Same speed as GPTQ/AWQ, better quality.**
|
| 87 |
+
|
| 88 |
+
## Important Flags
|
| 89 |
+
|
| 90 |
+
| Flag | Why |
|
| 91 |
+
|------|-----|
|
| 92 |
+
| `--language-model-only` | Qwen3.5 is multimodal — this skips the vision encoder (we only quantized text) |
|
| 93 |
+
| `--enforce-eager` | Required on Blackwell GPUs (cc 12.0). Optional on A100/H100 (faster without it) |
|
| 94 |
+
|
| 95 |
+
## Links
|
| 96 |
+
|
| 97 |
+
- Paper: [arxiv.org/abs/2603.29078](https://arxiv.org/abs/2603.29078)
|
| 98 |
+
- GitHub: [github.com/caiovicentino/polarengine-vllm](https://github.com/caiovicentino/polarengine-vllm)
|
| 99 |
+
- PyPI: `pip install polarquant`
|
| 100 |
+
- Base model: [Jackrong/Qwopus3.5-27B-v3](https://huggingface.co/Jackrong/Qwopus3.5-27B-v3)
|
assets/chart_download.png
ADDED
|
assets/chart_vram.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen3_5ForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"bos_token_id": null,
|
| 6 |
+
"torch_dtype": "bfloat16",
|
| 7 |
+
"eos_token_id": 248046,
|
| 8 |
+
"image_token_id": 248056,
|
| 9 |
+
"model_name": "unsloth/Qwen3.5-27B",
|
| 10 |
+
"model_type": "qwen3_5",
|
| 11 |
+
"pad_token_id": 248055,
|
| 12 |
+
"text_config": {
|
| 13 |
+
"attention_bias": false,
|
| 14 |
+
"attention_dropout": 0.0,
|
| 15 |
+
"attn_output_gate": true,
|
| 16 |
+
"bos_token_id": null,
|
| 17 |
+
"torch_dtype": "bfloat16",
|
| 18 |
+
"eos_token_id": 248044,
|
| 19 |
+
"full_attention_interval": 4,
|
| 20 |
+
"head_dim": 256,
|
| 21 |
+
"hidden_act": "silu",
|
| 22 |
+
"hidden_size": 5120,
|
| 23 |
+
"initializer_range": 0.02,
|
| 24 |
+
"intermediate_size": 17408,
|
| 25 |
+
"layer_types": [
|
| 26 |
+
"linear_attention",
|
| 27 |
+
"linear_attention",
|
| 28 |
+
"linear_attention",
|
| 29 |
+
"full_attention",
|
| 30 |
+
"linear_attention",
|
| 31 |
+
"linear_attention",
|
| 32 |
+
"linear_attention",
|
| 33 |
+
"full_attention",
|
| 34 |
+
"linear_attention",
|
| 35 |
+
"linear_attention",
|
| 36 |
+
"linear_attention",
|
| 37 |
+
"full_attention",
|
| 38 |
+
"linear_attention",
|
| 39 |
+
"linear_attention",
|
| 40 |
+
"linear_attention",
|
| 41 |
+
"full_attention",
|
| 42 |
+
"linear_attention",
|
| 43 |
+
"linear_attention",
|
| 44 |
+
"linear_attention",
|
| 45 |
+
"full_attention",
|
| 46 |
+
"linear_attention",
|
| 47 |
+
"linear_attention",
|
| 48 |
+
"linear_attention",
|
| 49 |
+
"full_attention",
|
| 50 |
+
"linear_attention",
|
| 51 |
+
"linear_attention",
|
| 52 |
+
"linear_attention",
|
| 53 |
+
"full_attention",
|
| 54 |
+
"linear_attention",
|
| 55 |
+
"linear_attention",
|
| 56 |
+
"linear_attention",
|
| 57 |
+
"full_attention",
|
| 58 |
+
"linear_attention",
|
| 59 |
+
"linear_attention",
|
| 60 |
+
"linear_attention",
|
| 61 |
+
"full_attention",
|
| 62 |
+
"linear_attention",
|
| 63 |
+
"linear_attention",
|
| 64 |
+
"linear_attention",
|
| 65 |
+
"full_attention",
|
| 66 |
+
"linear_attention",
|
| 67 |
+
"linear_attention",
|
| 68 |
+
"linear_attention",
|
| 69 |
+
"full_attention",
|
| 70 |
+
"linear_attention",
|
| 71 |
+
"linear_attention",
|
| 72 |
+
"linear_attention",
|
| 73 |
+
"full_attention",
|
| 74 |
+
"linear_attention",
|
| 75 |
+
"linear_attention",
|
| 76 |
+
"linear_attention",
|
| 77 |
+
"full_attention",
|
| 78 |
+
"linear_attention",
|
| 79 |
+
"linear_attention",
|
| 80 |
+
"linear_attention",
|
| 81 |
+
"full_attention",
|
| 82 |
+
"linear_attention",
|
| 83 |
+
"linear_attention",
|
| 84 |
+
"linear_attention",
|
| 85 |
+
"full_attention",
|
| 86 |
+
"linear_attention",
|
| 87 |
+
"linear_attention",
|
| 88 |
+
"linear_attention",
|
| 89 |
+
"full_attention"
|
| 90 |
+
],
|
| 91 |
+
"linear_conv_kernel_dim": 4,
|
| 92 |
+
"linear_key_head_dim": 128,
|
| 93 |
+
"linear_num_key_heads": 16,
|
| 94 |
+
"linear_num_value_heads": 48,
|
| 95 |
+
"linear_value_head_dim": 128,
|
| 96 |
+
"mamba_ssm_dtype": "float32",
|
| 97 |
+
"max_position_embeddings": 262144,
|
| 98 |
+
"mlp_only_layers": [],
|
| 99 |
+
"model_type": "qwen3_5_text",
|
| 100 |
+
"mtp_num_hidden_layers": 1,
|
| 101 |
+
"mtp_use_dedicated_embeddings": false,
|
| 102 |
+
"num_attention_heads": 24,
|
| 103 |
+
"num_hidden_layers": 64,
|
| 104 |
+
"num_key_value_heads": 4,
|
| 105 |
+
"pad_token_id": null,
|
| 106 |
+
"partial_rotary_factor": 0.25,
|
| 107 |
+
"rms_norm_eps": 1e-06,
|
| 108 |
+
"rope_parameters": {
|
| 109 |
+
"mrope_interleaved": true,
|
| 110 |
+
"mrope_section": [
|
| 111 |
+
11,
|
| 112 |
+
11,
|
| 113 |
+
10
|
| 114 |
+
],
|
| 115 |
+
"partial_rotary_factor": 0.25,
|
| 116 |
+
"rope_theta": 10000000,
|
| 117 |
+
"rope_type": "default"
|
| 118 |
+
},
|
| 119 |
+
"tie_word_embeddings": false,
|
| 120 |
+
"use_cache": true,
|
| 121 |
+
"vocab_size": 248320
|
| 122 |
+
},
|
| 123 |
+
"tie_word_embeddings": false,
|
| 124 |
+
"unsloth_fixed": true,
|
| 125 |
+
"unsloth_version": "2026.3.18",
|
| 126 |
+
"use_cache": false,
|
| 127 |
+
"video_token_id": 248057,
|
| 128 |
+
"vision_config": {
|
| 129 |
+
"deepstack_visual_indexes": [],
|
| 130 |
+
"depth": 27,
|
| 131 |
+
"torch_dtype": "bfloat16",
|
| 132 |
+
"hidden_act": "gelu_pytorch_tanh",
|
| 133 |
+
"hidden_size": 1152,
|
| 134 |
+
"in_channels": 3,
|
| 135 |
+
"initializer_range": 0.02,
|
| 136 |
+
"intermediate_size": 4304,
|
| 137 |
+
"model_type": "qwen3_5",
|
| 138 |
+
"num_heads": 16,
|
| 139 |
+
"num_position_embeddings": 2304,
|
| 140 |
+
"out_hidden_size": 5120,
|
| 141 |
+
"patch_size": 16,
|
| 142 |
+
"spatial_merge_size": 2,
|
| 143 |
+
"temporal_patch_size": 2
|
| 144 |
+
},
|
| 145 |
+
"vision_end_token_id": 248054,
|
| 146 |
+
"vision_start_token_id": 248053,
|
| 147 |
+
"quantization_config": {
|
| 148 |
+
"quant_method": "compressed-tensors",
|
| 149 |
+
"format": "pack-quantized",
|
| 150 |
+
"quantization_status": "compressed",
|
| 151 |
+
"global_compression_ratio": 4.0,
|
| 152 |
+
"config_groups": {
|
| 153 |
+
"group_0": {
|
| 154 |
+
"targets": [
|
| 155 |
+
"Linear"
|
| 156 |
+
],
|
| 157 |
+
"weights": {
|
| 158 |
+
"num_bits": 4,
|
| 159 |
+
"type": "int",
|
| 160 |
+
"symmetric": true,
|
| 161 |
+
"strategy": "group",
|
| 162 |
+
"group_size": 128,
|
| 163 |
+
"dynamic": false,
|
| 164 |
+
"block_structure": null
|
| 165 |
+
},
|
| 166 |
+
"input_activations": null,
|
| 167 |
+
"output_activations": null
|
| 168 |
+
}
|
| 169 |
+
},
|
| 170 |
+
"ignore": [
|
| 171 |
+
"lm_head",
|
| 172 |
+
"embed_tokens",
|
| 173 |
+
"re:.*in_proj_a$",
|
| 174 |
+
"re:.*in_proj_b$",
|
| 175 |
+
"re:visual\\..*",
|
| 176 |
+
"re:.*vision.*"
|
| 177 |
+
]
|
| 178 |
+
}
|
| 179 |
+
}
|
model-00001.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:74596882a9d73ba395ee3f8a6c5b08243ff7bea06ee711d3bcc127f6e905d9c7
|
| 3 |
+
size 6875108400
|
model-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8462a3fe9297b49d7d60c5a1d09759af91d40abc387cacab5a2c85702cadb4dd
|
| 3 |
+
size 5010862512
|
model-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:57b743210c8c8166865ce158e97dc276691c34deda2a9ee32ce30b94f430d3bf
|
| 3 |
+
size 3247759400
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
polar_config.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"method": "PolarQuant",
|
| 3 |
+
"weight_bits": 5,
|
| 4 |
+
"kv_cache_bits": 3,
|
| 5 |
+
"block_size": 128,
|
| 6 |
+
"head_dim": 128,
|
| 7 |
+
"num_layers": 64,
|
| 8 |
+
"quantized_layers": 497,
|
| 9 |
+
"skipped_layers": 0,
|
| 10 |
+
"int4_group_size": 128,
|
| 11 |
+
"vram_gb": 19.1,
|
| 12 |
+
"base_model": "huihui-ai/Huihui-Qwopus3.5-27B-v3-abliterated",
|
| 13 |
+
"benchmark": {
|
| 14 |
+
"FP16": {
|
| 15 |
+
"tok_s": 21.804779849809538,
|
| 16 |
+
"peak_gb": 70.363202048,
|
| 17 |
+
"time": 4.586150407791138
|
| 18 |
+
},
|
| 19 |
+
"Q3": {
|
| 20 |
+
"tok_s": 22.092763850247692,
|
| 21 |
+
"peak_gb": 19.130801664,
|
| 22 |
+
"time": 4.526368935902913
|
| 23 |
+
},
|
| 24 |
+
"Q2": {
|
| 25 |
+
"tok_s": 22.038845106697618,
|
| 26 |
+
"peak_gb": 19.130801664,
|
| 27 |
+
"time": 4.537442843119304
|
| 28 |
+
}
|
| 29 |
+
}
|
| 30 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:87a7830d63fcf43bf241c3c5242e96e62dd3fdc29224ca26fed8ea333db72de4
|
| 3 |
+
size 19989343
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"audio_bos_token": "<|audio_start|>",
|
| 4 |
+
"audio_eos_token": "<|audio_end|>",
|
| 5 |
+
"audio_token": "<|audio_pad|>",
|
| 6 |
+
"backend": "tokenizers",
|
| 7 |
+
"bos_token": null,
|
| 8 |
+
"clean_up_tokenization_spaces": false,
|
| 9 |
+
"eos_token": "<|im_end|>",
|
| 10 |
+
"errors": "replace",
|
| 11 |
+
"image_token": "<|image_pad|>",
|
| 12 |
+
"is_local": false,
|
| 13 |
+
"model_max_length": 262144,
|
| 14 |
+
"model_specific_special_tokens": {
|
| 15 |
+
"audio_bos_token": "<|audio_start|>",
|
| 16 |
+
"audio_eos_token": "<|audio_end|>",
|
| 17 |
+
"audio_token": "<|audio_pad|>",
|
| 18 |
+
"image_token": "<|image_pad|>",
|
| 19 |
+
"video_token": "<|video_pad|>",
|
| 20 |
+
"vision_bos_token": "<|vision_start|>",
|
| 21 |
+
"vision_eos_token": "<|vision_end|>"
|
| 22 |
+
},
|
| 23 |
+
"pad_token": "<|vision_pad|>",
|
| 24 |
+
"padding_side": "right",
|
| 25 |
+
"pretokenize_regex": "(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\\r\\n\\p{L}\\p{N}]?[\\p{L}\\p{M}]+|\\p{N}| ?[^\\s\\p{L}\\p{M}\\p{N}]+[\\r\\n]*|\\s*[\\r\\n]+|\\s+(?!\\S)|\\s+",
|
| 26 |
+
"processor_class": "Qwen3VLProcessor",
|
| 27 |
+
"split_special_tokens": false,
|
| 28 |
+
"tokenizer_class": "Qwen2TokenizerFast",
|
| 29 |
+
"unk_token": null,
|
| 30 |
+
"video_token": "<|video_pad|>",
|
| 31 |
+
"vision_bos_token": "<|vision_start|>",
|
| 32 |
+
"vision_eos_token": "<|vision_end|>",
|
| 33 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}\n{%- for message in messages[::-1] %}\n {%- set index = (messages|length - 1) - loop.index0 %}\n {%- if ns.multi_step_tool and message.role == \"user\" and message.content is string and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}\n {%- set ns.multi_step_tool = false %}\n {%- set ns.last_query_index = index %}\n {%- endif %}\n{%- endfor %}\n{%- for message in messages %}\n {%- if message.content is string %}\n {%- set content = message.content %}\n {%- else %}\n {%- set content = '' %}\n {%- endif %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set reasoning_content = '' %}\n {%- if message.reasoning_content is string %}\n {%- set reasoning_content = message.reasoning_content %}\n {%- else %}\n {%- if '</think>' in content %}\n {%- set reasoning_content = content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- set content = content.split('</think>')[-1].lstrip('\\n') %}\n {%- endif %}\n {%- endif %}\n {%- if loop.index0 > ns.last_query_index %}\n {%- if loop.last or (not loop.last and reasoning_content) %}\n {{- '<|im_start|>' + message.role + '\\n<think>\\n' + reasoning_content.strip('\\n') + '\\n</think>\\n\\n' + content.lstrip('\\n') }}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\n<think>\n' }}\n{%- endif %}"
|
| 34 |
+
}
|